Research Report on Signal Processing Techniques: Speech Recognition Systems
Question
Task:
The purpose of the report is that the students will have an open research topic to explore on advanced signal processing techniques. One can choose research topic of interest and make a thorough literature analysis. You can go through IEEE Explore and ScienceDirect databases and choose any topic and go through the available literature and summarize your findings. You may use go through any other Internet resources, but they should be authentic. Some of the suggested signal processing topics include (but are not limited to):
Astronomy/ Space exploration
Biomedical applications
Communication
Speech Processing/Recognition
Radar signal processing
Oil/ Mining exploration
Undersea signal processing
While searching in IEEE Xplore/ ScienceDirect you may narrow-down the search space by limiting to Journals and Magazines
Answer
Abstract— Researchers now are working to improve the things computers can accomplish with spoken language. This study classifies the signal processing techniques used to translate spoken words into computer understandable form. A list and analysis of the current recognition algorithms' difficulties will be provided. The review concludes with a quick look at some of the uses for voice recognition technology.
Keywords— Speech Recognition Systems; Voice-to-Text; AI Voice; Alex; Siri, Google Assistant; ANN, Hidden Markov.
I. Introduction
This multidisciplinary discipline of computational linguistics develops strategies and technology to make it easier for computers to recognize and translate spoken speech into written representation. "Speech to text" is another name for this technology (STT). Computer science plus electrical engineering expertise and research is included. As the goal of voice recognition, it's important to have a computer that can recognize and respond on spoken words [2][3][4][5].
II. Literature review
A. Speech Recognition Architecture
These components make up a typical voice recognition system, and they are depicted in the diagram below: acoustical front-end; an audio model; a dictionary; and a decoder. The Acoustic front-end converts the speech signal into pertinent data for recognition by transforming the signal into suitable characteristics. When an audio waveform out of a microphone is inputted, a procedure known as feature extraction turns it into a series of fixed-size acoustical vectors. The word/phone model's parameters are estimated using the training data's acoustic vectors. In order to select the most likely word sequence to create, the decoder searches through all conceivable word sequences. P (O|W) is an acoustic model and P (W) is a language model that define the probability [4][5] or each phrase or sub-word unit, an automated recognition system extracts many speech characteristics from the acoustic voice stream. When the speech parameters change over time, they form a pattern that identifies a word or sub-word. Together these consisting of a combination the word or sub-word [3]. As part of the onboarding process, the operator will be required to read the whole application's vocabulary aloud. Word patterns are saved and afterwards matched to the templates when a word's pattern has to be identified, the word with the best match is chosen. Pattern recognition is the term used to describe this method”.
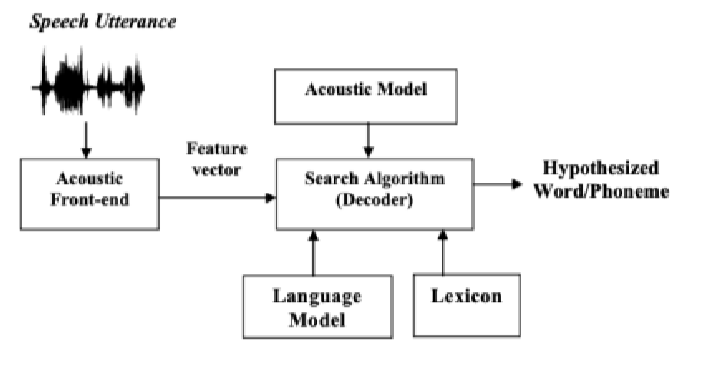
Figure 1
- Acoustic Front-end - Feature extraction and signal processing are also part of the acoustic front end. At the feature extraction stage of voice recognition, the major aim is a compact representation of said input signal by computing a sparse series of feature vectors. Three phases of feature extraction are commonly used 4]. In the first stage, the signal is subjected to some sort of spectral temporal analysis, and then raw characteristics representing the power spectrum envelope of brief speech intervals are generated. A take numerous forms vector is created in the second stage by combining dynamic and static characteristics. The final stage (that is not usually present) reduces the size and robustness of the expanded feature vectors so that they may be sent to the recognizer directly.
- Language Model - Acoustic models contain acoustic properties for phonetic units to be identified and are therefore crucial knowledge sources for automated speech recognition systems. They are used. Choosing basic modelling units is a critical problem when creating an acoustic model.
- Decoder - Using the acoustic-phonetic-language model as well as the observational sequence O, identify the most probable keep it consistent W in the decoding step. Decoding may be made easier with the use of dynamic programming. It's more important to select a single path across the network that best matches O than to evaluate the probabilities of all other model paths that produce it [1].
Acoustic Model - Acoustic models represent acoustic properties for phonetic units to be identified and are therefore crucial knowledge sources for automated speech processing. One of the most crucial aspects of creating an acoustic model is deciding on the basic modelling components.
B. Challenges
- Approach via utterance - What it alludes to is whether or not a speaker speaks in an isolated or linked fashion:
-
- When using an isolated word voice recognition system, this same speaker must take a short pause between each word. Neither any single word is recognised, but one utterance is at a time is involved.
- Interconnected word systems are similar to isolated words, but they enable for independent utterances to just be "run-together" with just a minimal gap in between them.
- Utterance style - Everyone communicates in a unique way since it's a way for them to show who they are. Besides using their own terminology, they also have a distinctive method of articulating and emphasising. In addition, the manner in which he speaks varies depending on the occasion. Humans may express their feelings verbally as well. When someone is pleased, depressed, annoyed, nervous, agitated, or trying to protect themselves, they will speak differently than when they are not. There are two primary categories: continuous speaking and spontaneous speech. [6]
- For example, in "continuous speech," adjacent words are uttered simultaneously without any perceptible pauses or separation between them. This is known as "co-articulation." The development of continuous speech recognition systems is exceedingly difficult due to the necessity of determining utterance boundaries in unusual ways. Confusability between distinct word sequences grows in line with the number of vocabulary words.
- It is significantly more difficult to discern disfluencies in spontaneity or extemporaneous discourse than in speech read from just a script. In addition, the vocabulary is virtually endless; therefore the system should be able to deal intelligently with unfamiliar terms. It's really challenging since it's full of distortions like "uh" as well as "um," false beginnings, imperfect sentences, coughing, and giggling.
- Types of Speaker Model - Due to the uniqueness of their physical bodies and personalities, all speakers have distinctive voices. The two primary categories of speech recognition systems are speaker dependent versus speaker independent, based on the speaker models :
- A speech dependent system is designed to be used by a single speaker and requires the user to give samples of their voice before they can be used.
- Models that are not dependent on the speech of any one person are known as speaker independent models. This is the most difficult system to create because of the steep learning curve and worse accuracy compared to speaker-dependent systems.
- Vocabulary - The complexity, processing needs, and precision of a voice recognition system are all influenced by the vocabulary size. Others necessitate the use of huge dictionaries for a small number of applications (e.g. numbers alone) (e.g. dictation machines). The process of doing this gets increasingly difficult. Vocabularies in Speech Recognition Systems could be divided into the following groups:
- Communication Variability - The viewpoints from which the sound wave is spoken are one aspect of variability. When it comes to noise, the problem is compounded by the many different types of microphones and other devices that might affect a sound wave's content, from either the speaker all the way to a computer's separate representation [8]. Channel variability is the term used to describe this phenomenon. Additional factors that complicate voice recognition include environmental unpredictability, gender and age differences, and speech rate.
C. Techniques for Speech Recognition
There are three phases to the speaker recognition process. To begin with, the system receives the voice input and performs pre-processing activities in order to analyze it.
- Analysis - Speech recognition is hampered by noise and becomes less accurate as a result. Before feeding the extracted features block, tidy up the audio signals for the best outcomes. Preprocessing is used to achieve this. Noise reduction is achieved by utilizing zero-crossing rate as well as energy. Using energy & zero-crossing rate to separate spoken and unspoken dialogue yields the best results[7] [5].[7] [5].
- Feature Extraction - A variety of feature extraction approaches may be used to extract the unique properties included in spoken words from each utterance, which can then be used for a voice recognition challenge. Extracted characteristics must be stable throughout time and unaffected by noise or the environment. [8]. There are several feature extraction methods, including:
- Coefficients of Mel-Frequency Cepstrums (MFCC)
- Coding using Linear Predictive Linearization (LPC)
- Cepstral Prediction Coefficients for Linear Models (LPCC),
- Linear (LDA),
- The Prediction of Perceptual Linearity (PLP)
- Discriminant Analysis as well as the
- Wavelet Transform Discrete (DWT)
- Classification - To cope with speech fluctuation and understand how a particular utterance relates to a particular word or words, speech recognition processes must take this into consideration.
- Acoustic Phonetic - Instead of identifying speech sounds and labelling them, only the Acoustic Phonetic method relied on discovery and labelling. In the acoustic phonetic approach, permanent, differentiating phonetic units termed phonemes are hypothesized and are generally viewed as acoustics qualities present in speech [4].
- Approach based on Recognizing Patterns - A large amount of different samples can be divided into classes by training or developing a system (with a feature vector) that does so [2].
- Template based - An technique that utilizes a template has a library of illustrative speech patterns. As a result, these patterns are kept as a dictionary's citation patterns. By comparing an unknown spoken utterance to all of these references templates, speech may be recorded [3]. The category of best match is chosen. Templates for whole phrases are typically created. Phonemes, which are smaller acoustically more changeable components, can be segmented or classified to avoid making mistakes.
- Dynamic distortion of time - Dynamic time warping is very much an approach for comparing the similarity of two time or speed-varying sequences. To find the best match amongst two sequences under specific limitations, DTW is used.
- Hidden Markov Model - In order to create time-varying spectral vector sequences, Hidden Markov Models (HMMs) provide an easy-to-use framework. Consequently, practically all current large lexicon continual speech recognition (LVCSR) programs depend on HMMs to some degree or another. A, B, and are the parameters that describe the HMM model, while is the framework of N states and M observations: = (A, B, ); and where A = aij, B = bj (wk), and 1 I, j N and 1 K = M [10]
- Neural Network - Using neural networks as part of the audio modelling process is another option. To find complicated nonlinear correlations between outputs and inputs data sets, an artificial neural network (ANN) uses a flexible mathematical design.[1].
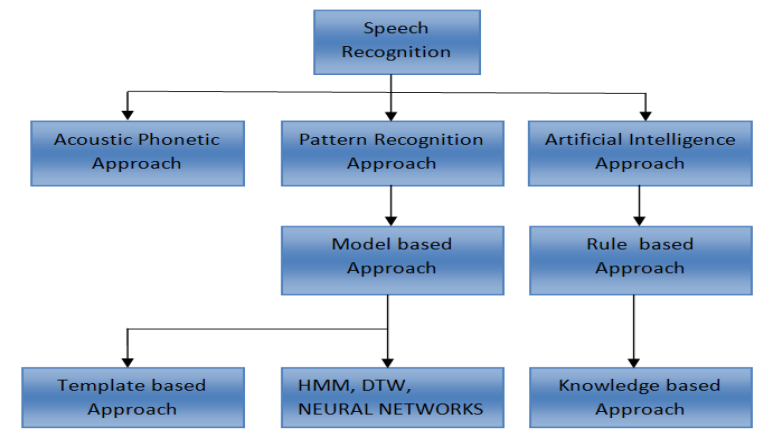
Figure 2
III. Conclusion
This paper discusses numerous techniques to feature extraction including pattern matching possible for voice recognition systems, as well as the principles of speech recognition. Recognition systems have recently put a variety of cutting-edge categorization algorithms to the test. These methods can speed up speech recognition while also improving the quality of said recognition. The problem usually occurs because the speech changes over time, and this, along with background noise, makes accurate speech recognition difficult. Moving forward, the emphasis will be on developing speech recognition systems with big vocabulary and speaker independence that can recognise speech in real time
References
[1] A. SAYEM, “Speech Analysis for Alphabets in Bangla Language: Automatic Speech Recognition,” International Journal of Engineering Research, vol. 3, no. 2, pp. 88–93, Feb. 2014, doi: 10.17950/ijer/v3s2/211.
[2] L. Schoneveld, A. Othmani, and H. Abdelkawy, “Leveraging Recent Advances in Deep Learning for Audio-Visual Emotion Recognition,” Pattern Recognition Letters, Mar. 2021, doi: 10.1016/j.patrec.2021.03.007.
[3] C. H. YOU and B. MA, “Spectral-domain speech enhancement for speech recognition,” Speech Communication, vol. 94, pp. 30–41, Nov. 2017, doi: 10.1016/j.specom.2017.08.007.
[4] M. Khademian and M. M. Homayounpour, “Monaural multi-talker speech recognition using factorial speech processing models,” Speech Communication, vol. 98, pp. 1–16, Apr. 2018, doi: 10.1016/j.specom.2018.01.007.
[5] B. Das, S. Mandal, P. Mitra, and A. Basu, “Aging speech recognition with speaker adaptation techniques: Study on medium vocabulary continuous Bengali speech, signal processing techniques” Pattern Recognition Letters, vol. 34, no. 3, pp. 335–343, Feb. 2013, doi: 10.1016/j.patrec.2012.10.029.
[6] B. Kar and A. Dey, “Speaker Recognition Using Audio Spectrum Projection and Vector Quantization,” International journal of simulation: systems, science & technology, Aug. 2018, doi: 10.5013/ijssst.a.19.04.11.
[7] A. Palanivinayagam and S. Nagarajan, “An optimized iterative clustering framework for recognizing speech,” International Journal of Speech Technology, Jul. 2020, doi: 10.1007/s10772-020-09728-5.
[8] S. King, “Measuring a decade of progress in Text-to-Speech,” Loquens, vol. 1, no. 1, p. e006, Jun. 2014, doi: 10.3989/loquens.2014.006.
[9] S. M. Siniscalchi, J. Reed, T. Svendsen, and C.-H. Lee, “Universal attribute characterization of spoken languages for automatic spoken language recognition,” Computer Speech & Language, vol. 27, no. 1, pp. 209–227, Jan. 2013, doi: 10.1016/j.csl.2012.05.001.
[10] J. Barker, N. Ma, A. Coy, and M. Cooke, “Speech fragment decoding techniques for simultaneous speaker identification and speech recognition,” Computer Speech & Language, vol. 24, no. 1, pp. 94–111, Jan. 2010, doi: 10.1016/j.csl.2008.05.003.